
Hi, I'm Loris, an AI Research Leader & Adjunct Professor with 15+ years of experience in AI between academia and big tech. My research focus is in adaptive and collaborative multimodal learning and generation.
~10 yrs
at Amazon
8+
Products Launched
$100M+
Business Impact
50+
Publications
6900+
Citations
28
H-index
 The Data Space: Controllable Multimodal Data Generation & Privacy
The Data Space: Controllable Multimodal Data Generation & Privacy
 The Model Space: Multimodal Adaptation & Specialization
The Model Space: Multimodal Adaptation & Specialization
 The Interaction Space: Human-AI Co-Design
The Interaction Space: Human-AI Co-Design
 The Industry Space: Clear Impact on Real-world Use Cases
The Industry Space: Clear Impact on Real-world Use Cases
2026-now

Founding Research Leader @ Stealth AI Start-up
2025-now
Adjunct Professor and Honorary Research Fellow (Part-time) @ University of Verona
Driving multidisciplinary academic research on adaptive and collaborative multimodal intelligence for digital services and MedTech.
Collaborating with research institutes and universities at global scale.
Developing talent pathways by teaching Data Visualization to Master's level Data Science cohorts.
2016-2025
Principal Scientist @ Amazon
Led high-impact core research and launched 8+ products across Prime Video, Alexa, and mobile/.com shopping generating $100M+ in business impact, related to movies and TV series autotagging, image accessibility, live sports highlights, virtual try-on, interactive product recommendations, and shopping assistants, used by millions of users worldwide.
I led scientists and developed novel models and architectures for video understanding, vision-language representation, Large Multimodal Models, and diffusion models.
2014-2015
Postdoc @ Dartmouth College
Research on video understanding, saliency in videos and object localization and detection. Collaborating with Prof. Lorenzo Torresani and Prof. Hugo Larochelle.
2011-2013
Postdoc @ Italian Institute of Technology
Research on video understanding, object recognition, Bayesian networks and Kernel-based methods. Collaborating with Prof. Vittorio Murino.
2009-2012
PhD in Computer Vision and Machine Learning @ University of Verona
Research on person re-identification, video understanding, tracking and attentional models. Supervised by Prof. Vittorio Murino and Prof. Marco Cristani.
2010
Visiting Student @ University of British Columbia
Collaborating with Prof. Nando de Freitas and Prof. Hugo Larochelle.
📢 News
- Jun 22, 2026: Invited speaker at the 2026 summer school on Advanced Topics in AI at the Zhejiang Normal University. Thanks Marcello!
- Jun 12, 2026: 1/1 papers accepted at MICCAI 2026!
- May 21, 2026: Call for paper of the workshop on Human-AI Co-Creation at ECCV 2026.
- May 19, 2026: Invited speaker on Adaptive and Collaborative Multimodal Intelligence at the University of Verona. Thanks Alessandro!
- May 15, 2026: I will serve as Program Chair at the ANAIS 2026.
- May 7, 2026: Obtained the Honorary Research Fellow position at University of Verona.
- May 4, 2026: I will serve as Area Chair for NeurIPS 2026.
- Apr 13, 2026: Workshop on Human-AI Co-Creation accepted at ECCV 2026
- Mar 2, 2026: Invited guest lecture at the Advanced Computer Vision course at the University of Utah. Thanks Ziad!
- Feb 21, 2026: 1/2 papers accepted at CVPR 2026!
- Dec 5, 2025: Invited speaker at the University of Trento and FBK. Thanks Yiming!
- Nov 28, 2025: Invited speaker at the Turin AI Fall School 2025. Thanks Tatiana!
- Oct 27, 2025: Invited speaker at the IIT. Thanks Vittorio!
- Oct 01, 2025: After nearly 10 intense and rewarding years at Amazon, I’ve decided it’s time to move on. More details in my LinkedIn post.
- Oct 01, 2025: Teaching the master course Data Visualization at University of Verona.
- Aug 9, 2025: 1/2 papers accepted at ICCV 2025!
📝 Research, Publications and Patents [Google Scholar]

Interactive Episodic Memory with User Feedback
N. Subedi, L. Bazzani, Z. Al-Halah
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
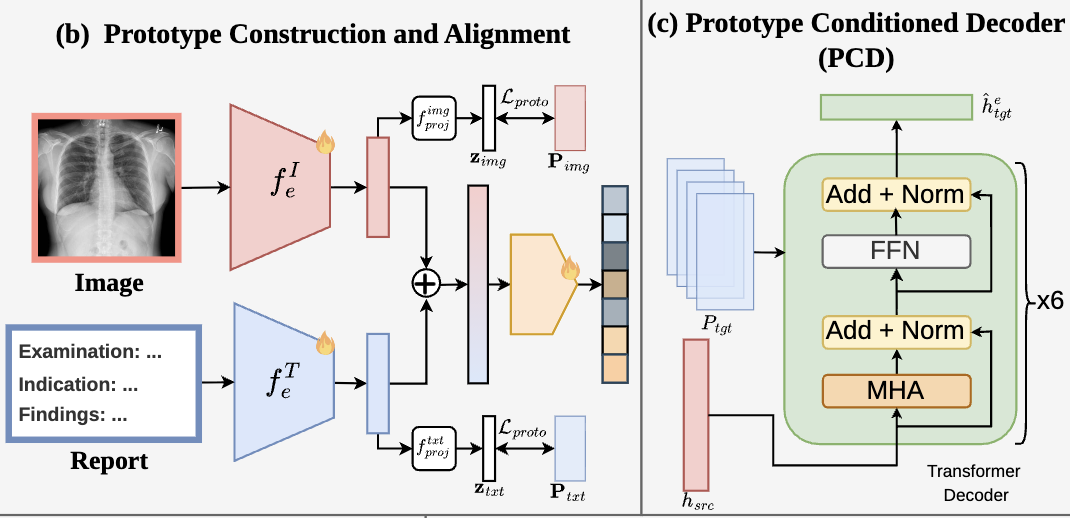
ProMoE-FL: Prototype-conditioned Mixture of Experts for Multimodal Federated Learning with Missing Modalities
A. Chhetri, B. Niroula, E. Vasquez, Y. R. Shrestha, P. K. Gyawali, L. Bazzani, B. Bhattarai
International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), 2026
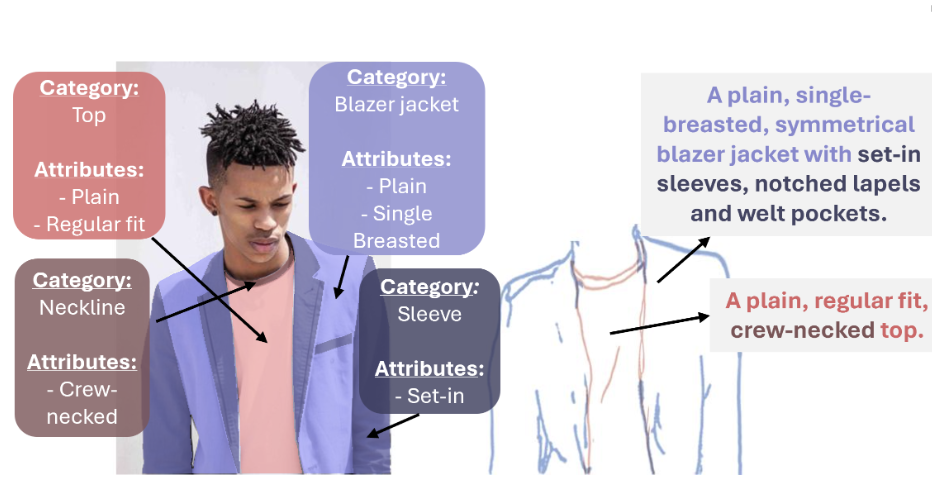
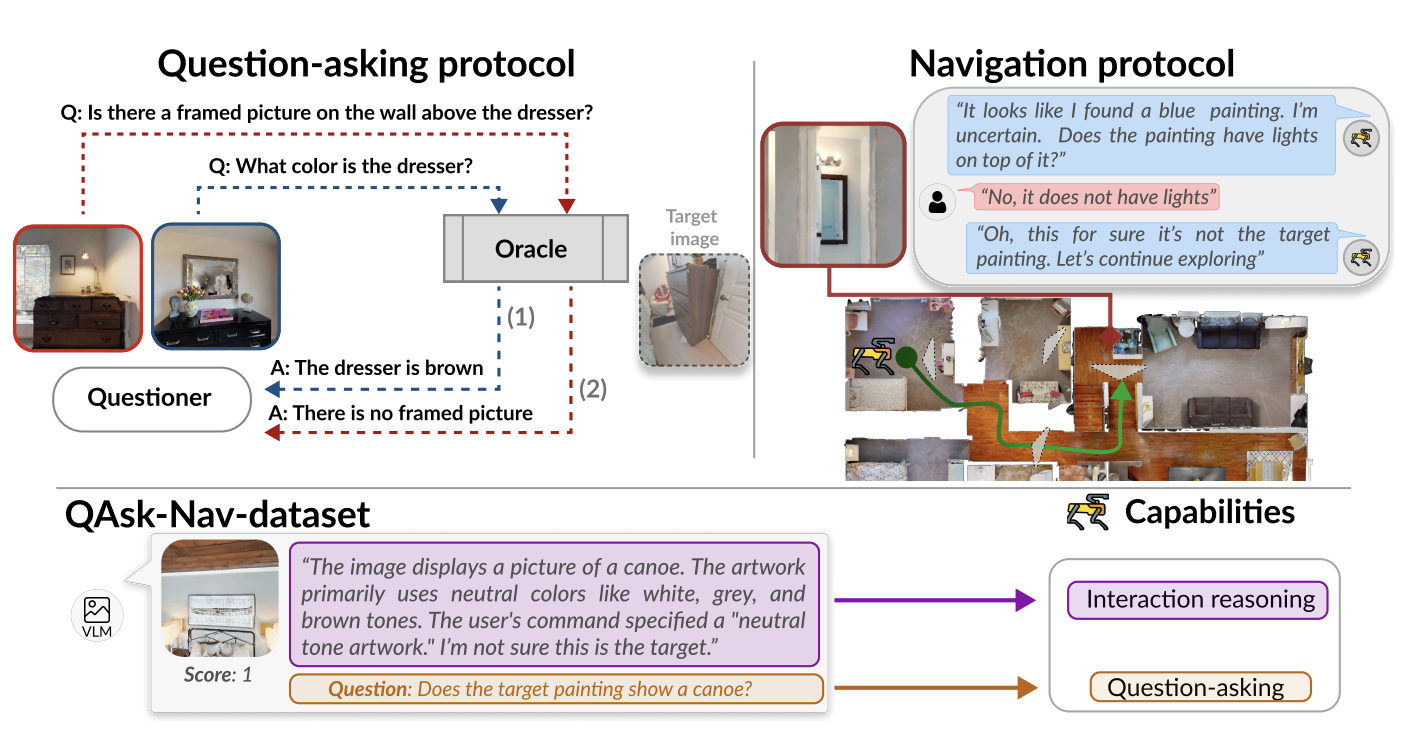
Benchmarking Interaction, Beyond Policy: a Reproducible Benchmark for Collaborative Instance Object Navigation
E. Zorzi, F. Taioli, Y. Wang, M. Cristani, A. Farinelli, A. Castellini, L. Bazzani
Arxiv, 2026
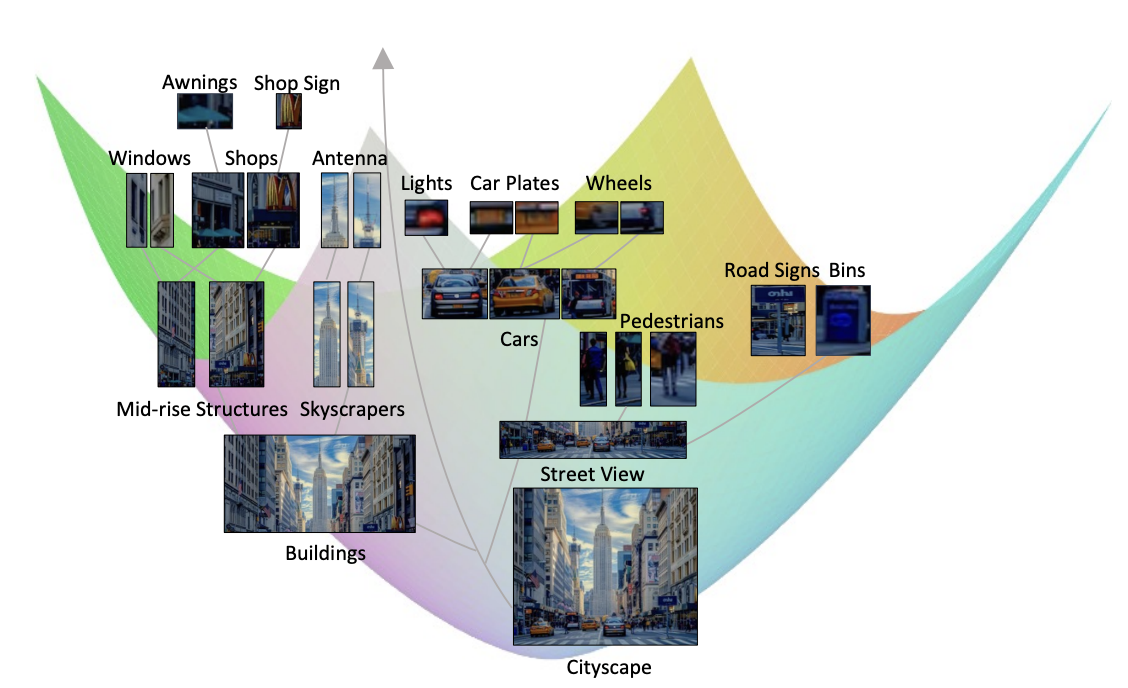
Learning Visual Hierarchies in Hyperbolic Space for Image Retrieval
Z. Wang, S. Ramasinghe, C. Xu, J. Monteil, L. Bazzani, T. Ajanthan
International Conference on Computer Vision (ICCV), 2025
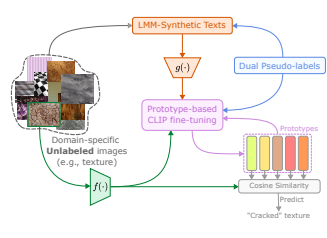
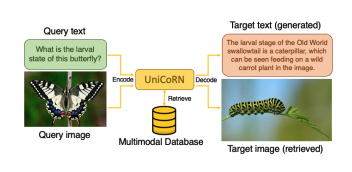
UniCoRN: Unified Commented Retrieval Network with LMMs
M. Jaritz, M. Guillaumin, S. Sternig, L. Bazzani
Arxiv, 2025
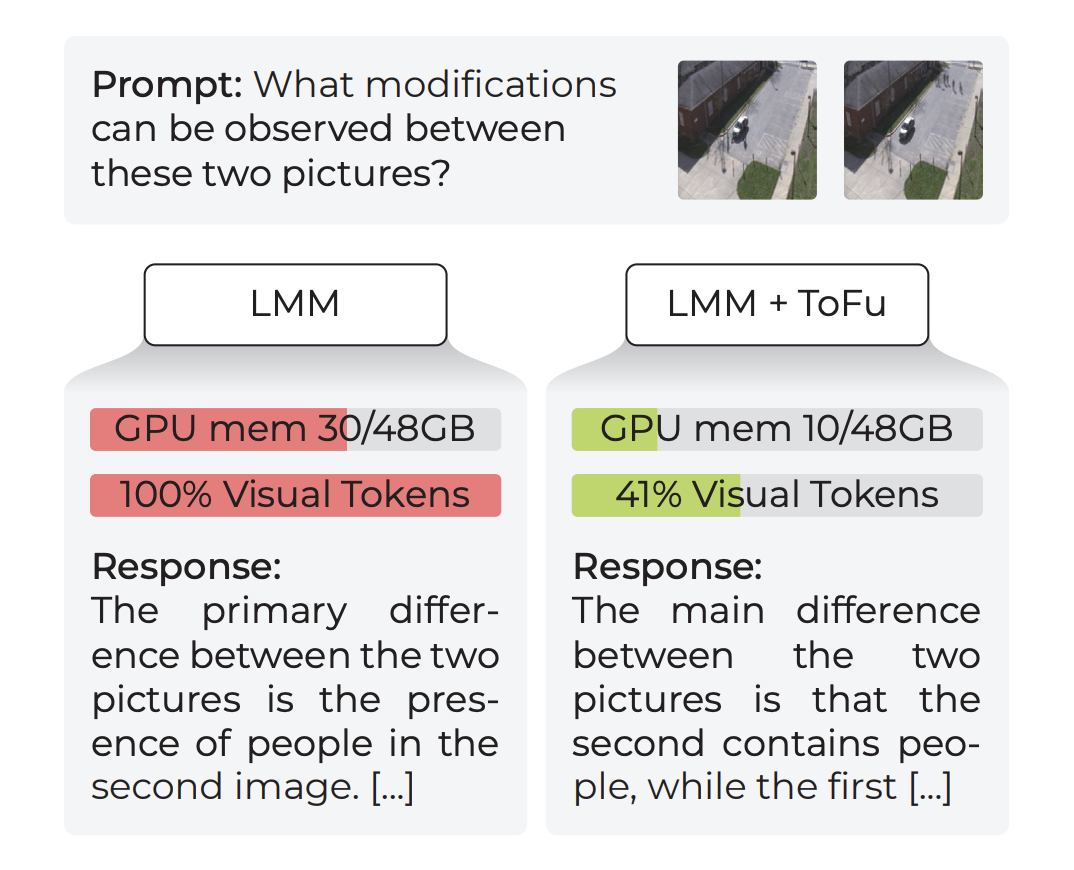
ToFu: Visual Tokens Reduction via Fusion for Multi-modal, Multi-patch, Multi-image Task
V. Pippi, M. Guillaumin, S. Casciarelli, R. Cucchiara, M. Jaritz, L. Bazzani
Arxiv, 2025
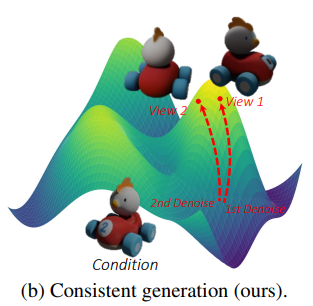

iEdit: Localised Text-guided Image Editing with Weak Supervision
R. Bodur, E. Gundogdu, B. Bhattarai, T-K Kim, M. Donoser, L. Bazzani
Computer Vision and Pattern Recognition (CVPR) Workshops, 2024

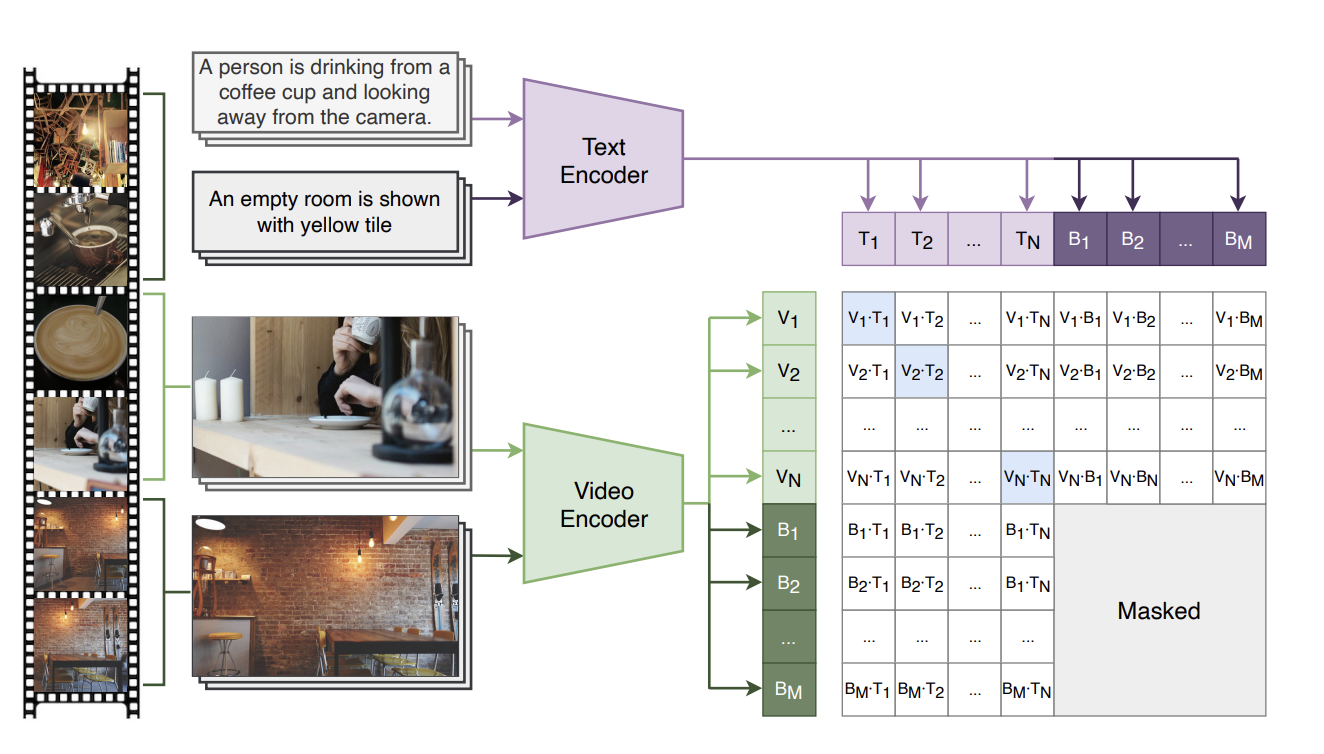
Contrastive Language-Action Pre-training for Temporal Localization
M. Xu, E. Gundogdu, M. Lapin, B. Ghanem, M. Donoser, L. Bazzani
Arxiv, 2022
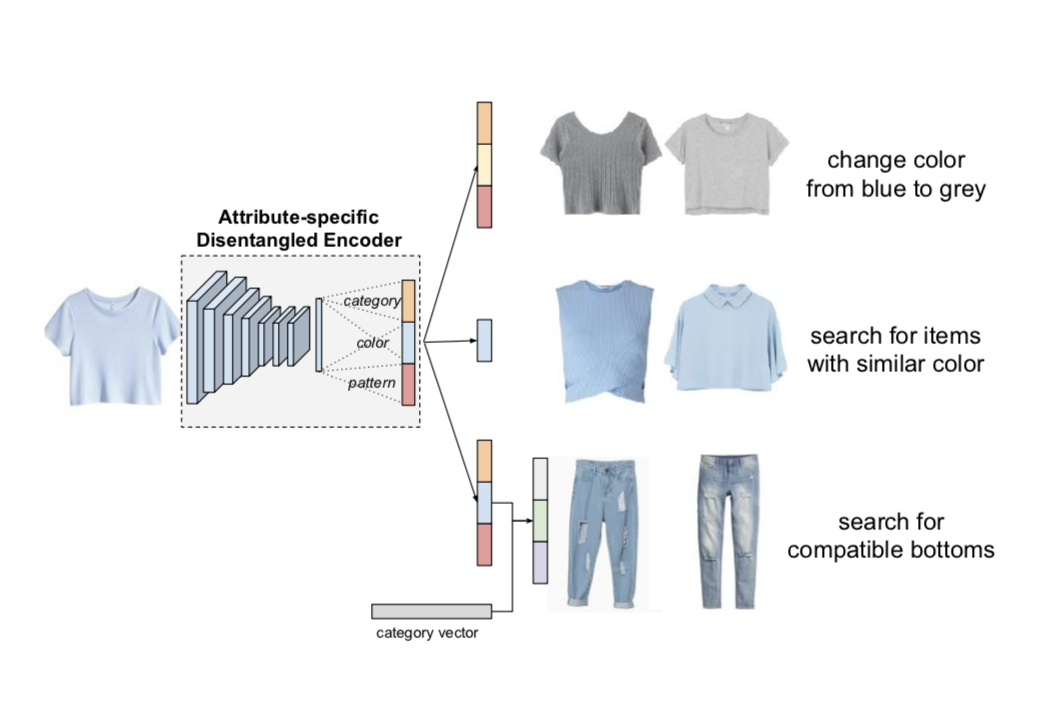
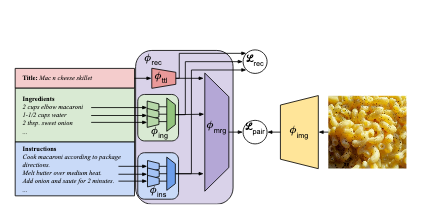
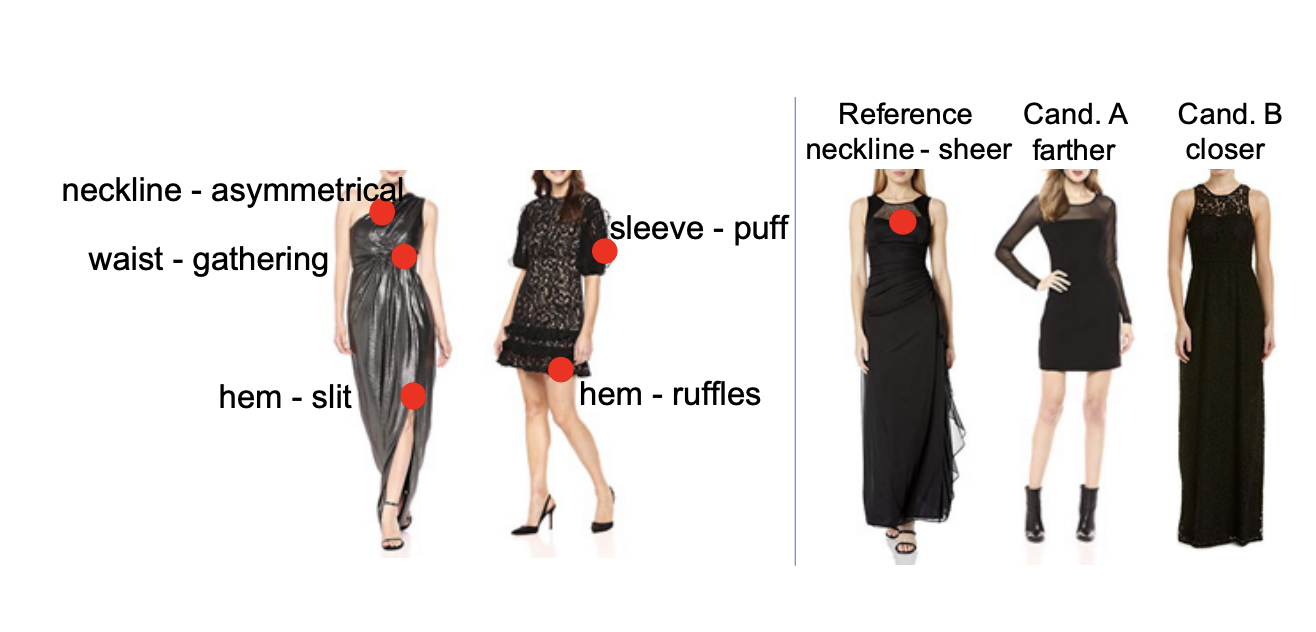
Localized Triplet Loss for Fine-Grained Fashion Image Retrieval
A. D’Innocente, N. Garg, Y. Zhang, L. Bazzani, M. Donoser
Computer Vision and Pattern Recognition (CVPR) Workshops, 2021
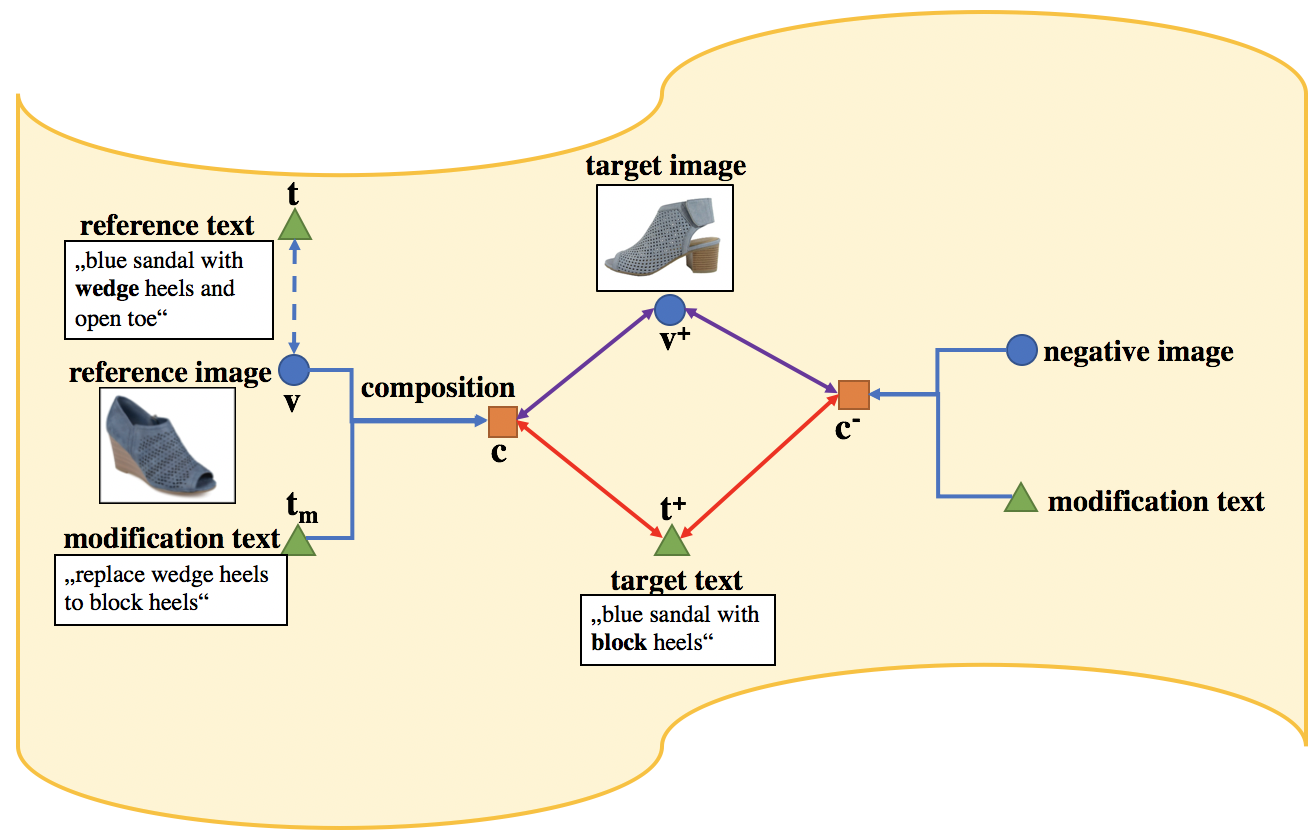
Learning Joint Visual Semantic Matching Embeddings for Language-guided Retrieval
Y. Chen, L. Bazzani
European Conference on Computer Vision (ECCV), 2020
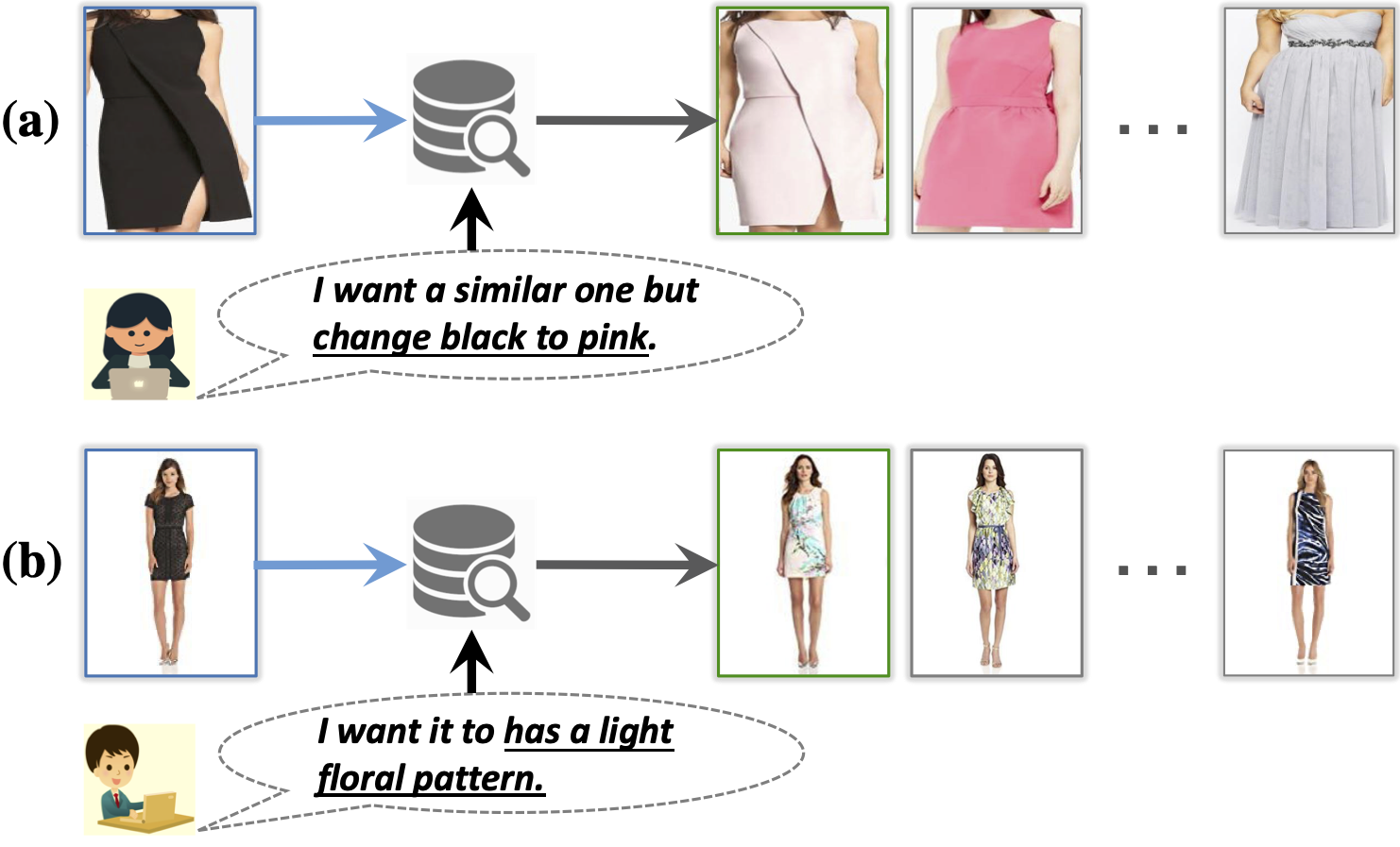

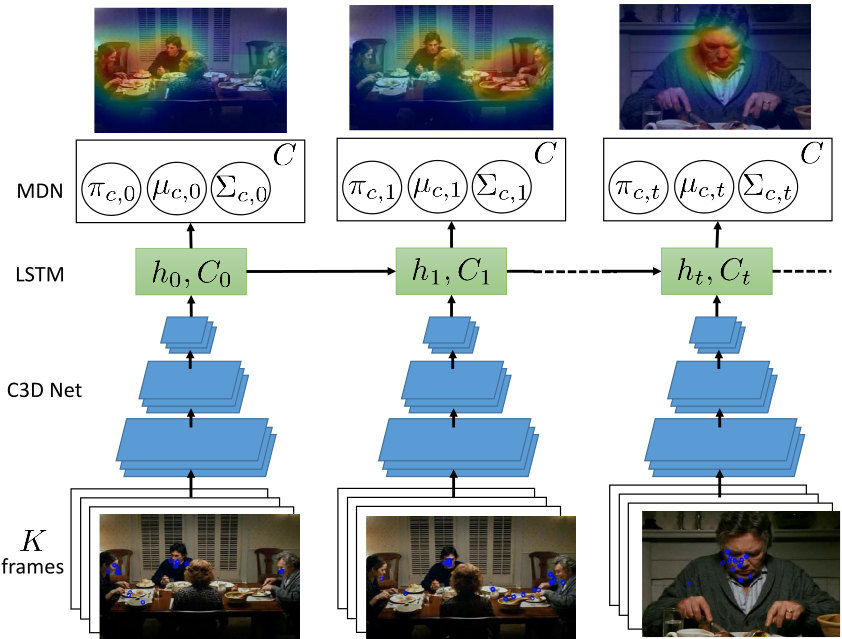
Group Detection and Tracking using Sociological Features
S. Vascon, and L. Bazzani
Group and Crowd Behavior for Computer Vision, 2017

Image and Video Understanding in Big Data
V. Murino, S. Gong, C. C. Loy and L. Bazzani
Special Issue in CVIU, 2017
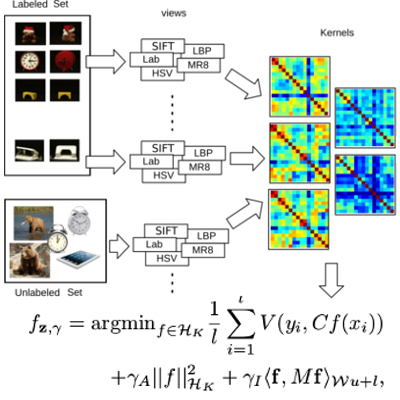
Approximate Log-Hilbert-Schmidt Distances Between Covariance Operators for Image Classification
H. Q. Minh, M. San Biagio, L. Bazzani, V. Murino
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016

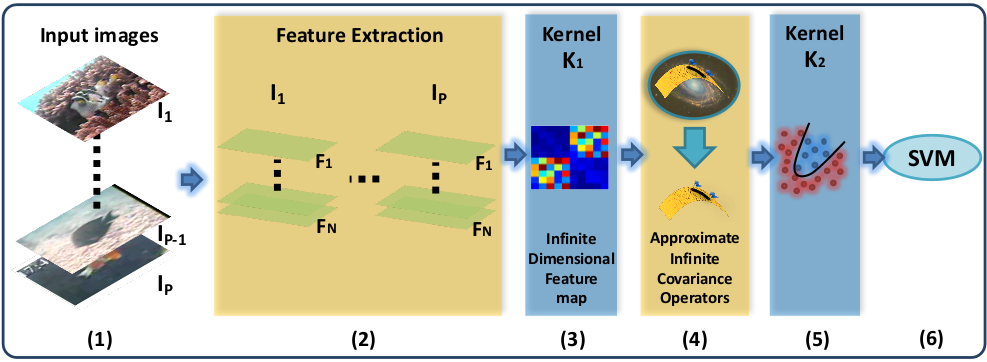
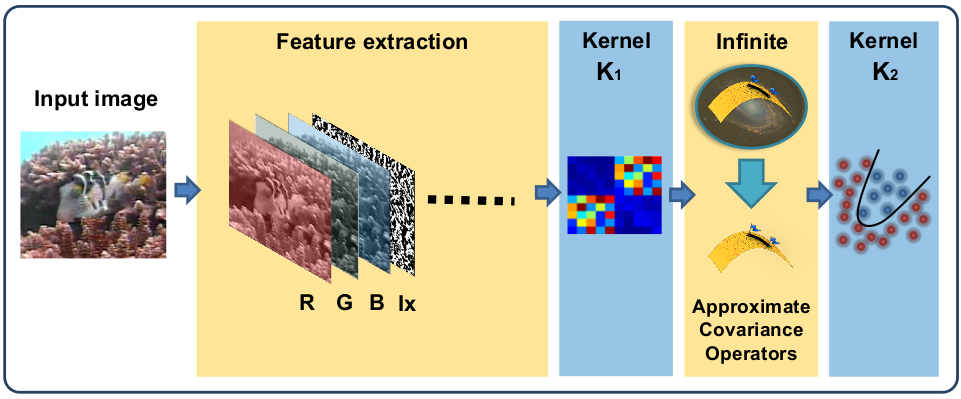
Kernel Methods on Approximate Infinite-Dimensional Covariance Operators for Image Classification
H. Q. Minh, M. San Biagio, L. Bazzani, V. Murino
Arxiv, 2016
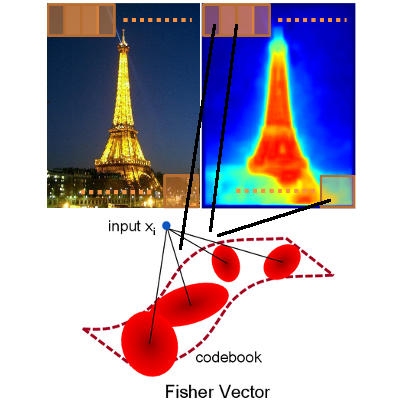
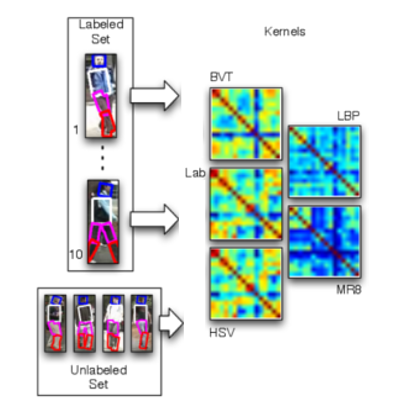
Weighted Bag of Visual Words for Object Recognition
L. Bazzani*, M. San Biagio*, M. Cristani, V. Murino
IEEE International Conference on Image Processing (ICIP), 2014
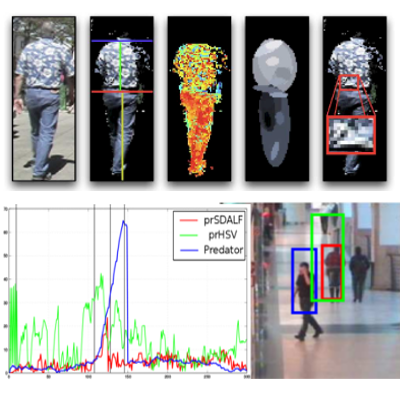
Semi-Supervised Multi-Feature Learning for Person Re-Identification
D. Figueira, L. Bazzani, H.Q. Minh, M. Cristani, A. Bernardino, V. Murino
International Conference on Advanced Video and Signal-based Surveillance (AVSS), 2013
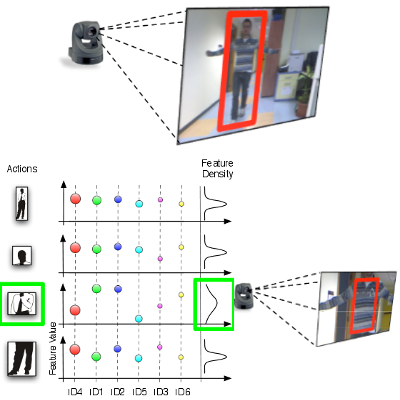
Person Re-Identification with a PTZ Camera: An Introductory Study
P. Salvagnini, L. Bazzani, M. Cristani, V. Murino
International Conference on Image Processing (ICIP), 2013
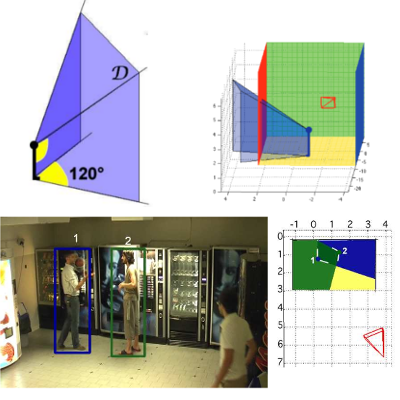
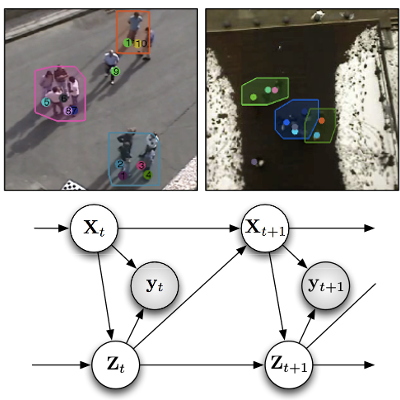
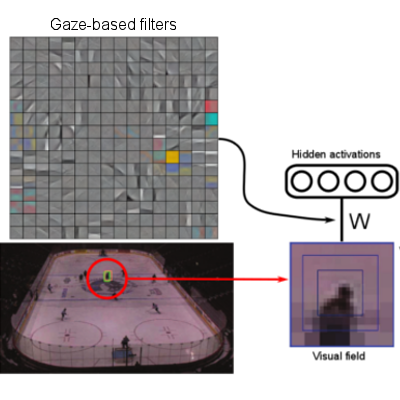
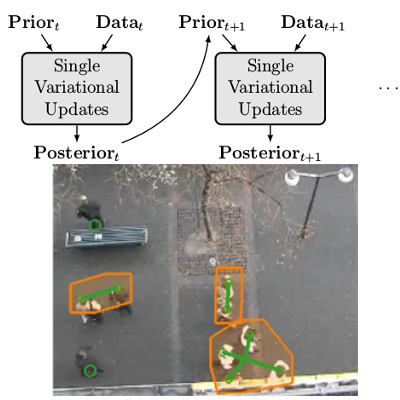
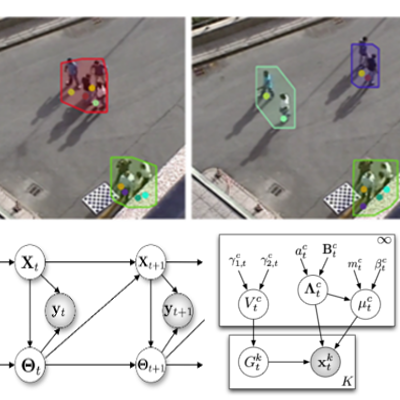
Online Bayesian Non-Parametrics for Social Group Detection
M. Zanotto, L. Bazzani, M. Cristani, V. Murino
British Machine Vision Conference (BMVC), 2012
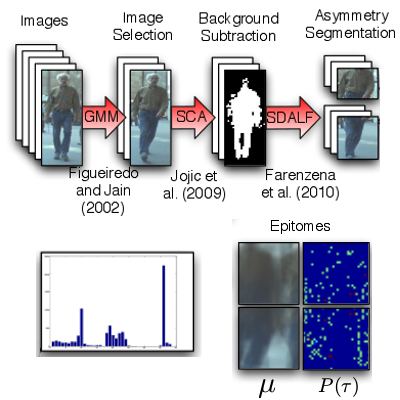
Multiple-Shot Person Re-Identification by Chromatic and Epitomic Analyses
L. Bazzani, M. Cristani, A. Perina, and V. Murino
Pattern Recognition Letters (PRL), 2012
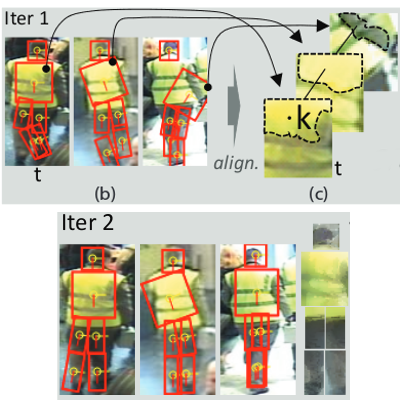
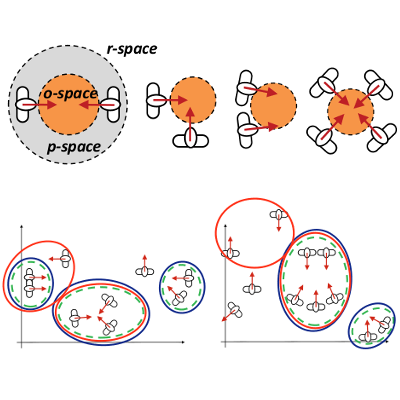
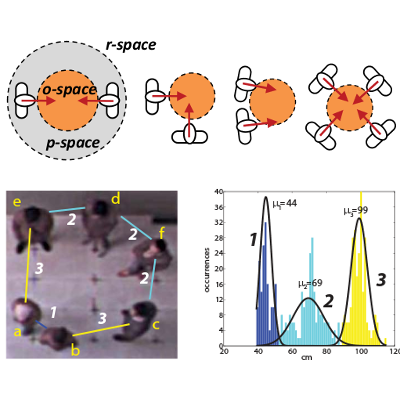
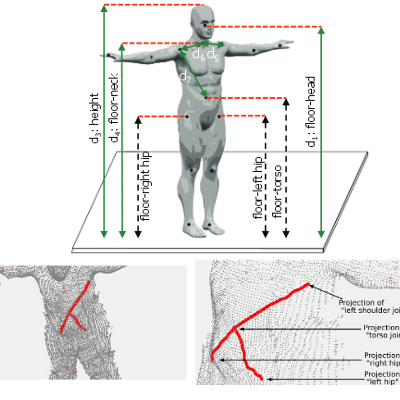
Towards Computational Proxemics: Inferring Social Relations from Interpersonal Distances
M. Cristani, G. Pagetti, A. Vinciarelli, L. Bazzani, G. Menegaz, V. Murino
International Conference on Social Computing (SocialCom), 2011
Multiple-Shot Person Re-Identification by HPE Signature
L. Bazzani, M. Cristani, A. Perina, M. Farenzena, V. Murino
International Conference on Pattern Recognition (ICPR), 2010

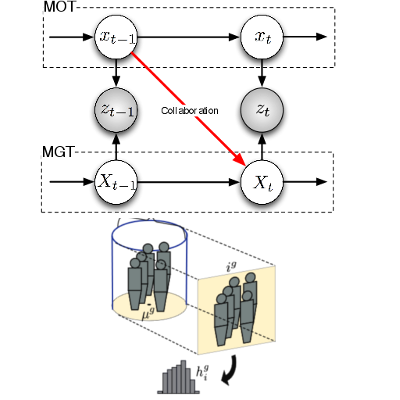
Collaborative Particle Filters for Group Tracking
L. Bazzani, M. Cristani, V. Murino
International Conference on Image Processing (ICIP), 2010
Multimodal Learning with Interaction/User Feedback
Interactive Episodic Memory with User Feedback
N. Subedi, L. Bazzani, Z. Al-Halah
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
Benchmarking Interaction, Beyond Policy: a Reproducible Benchmark for Collaborative Instance Object Navigation
E. Zorzi, F. Taioli, Y. Wang, M. Cristani, A. Farinelli, A. Castellini, L. Bazzani
Arxiv, 2026
Learning Visual Hierarchies in Hyperbolic Space for Image Retrieval
Z. Wang, S. Ramasinghe, C. Xu, J. Monteil, L. Bazzani, T. Ajanthan
International Conference on Computer Vision (ICCV), 2025
UniCoRN: Unified Commented Retrieval Network with LMMs
M. Jaritz, M. Guillaumin, S. Sternig, L. Bazzani
Arxiv, 2025
ToFu: Visual Tokens Reduction via Fusion for Multi-modal, Multi-patch, Multi-image Task
V. Pippi, M. Guillaumin, S. Casciarelli, R. Cucchiara, M. Jaritz, L. Bazzani
Arxiv, 2025
Localized Triplet Loss for Fine-Grained Fashion Image Retrieval
A. D’Innocente, N. Garg, Y. Zhang, L. Bazzani, M. Donoser
Computer Vision and Pattern Recognition (CVPR) Workshops, 2021
Learning Joint Visual Semantic Matching Embeddings for Language-guided Retrieval
Y. Chen, L. Bazzani
European Conference on Computer Vision (ECCV), 2020
Multimodal Federated Learning
ProMoE-FL: Prototype-conditioned Mixture of Experts for Multimodal Federated Learning with Missing Modalities
A. Chhetri, B. Niroula, E. Vasquez, Y. R. Shrestha, P. K. Gyawali, L. Bazzani, B. Bhattarai
International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), 2026
Multimodal Generative Models
iEdit: Localised Text-guided Image Editing with Weak Supervision
R. Bodur, E. Gundogdu, B. Bhattarai, T-K Kim, M. Donoser, L. Bazzani
Computer Vision and Pattern Recognition (CVPR) Workshops, 2024
Video Understanding
Contrastive Language-Action Pre-training for Temporal Localization
M. Xu, E. Gundogdu, M. Lapin, B. Ghanem, M. Donoser, L. Bazzani
Arxiv, 2022
Image and Video Understanding in Big Data
V. Murino, S. Gong, C. C. Loy and L. Bazzani
Special Issue in CVIU, 2017
Collaborative Particle Filters for Group Tracking
L. Bazzani, M. Cristani, V. Murino
International Conference on Image Processing (ICIP), 2010
Structured Methods for Images
Approximate Log-Hilbert-Schmidt Distances Between Covariance Operators for Image Classification
H. Q. Minh, M. San Biagio, L. Bazzani, V. Murino
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
Kernel Methods on Approximate Infinite-Dimensional Covariance Operators for Image Classification
H. Q. Minh, M. San Biagio, L. Bazzani, V. Murino
Arxiv, 2016
Weighted Bag of Visual Words for Object Recognition
L. Bazzani*, M. San Biagio*, M. Cristani, V. Murino
IEEE International Conference on Image Processing (ICIP), 2014
Behavioral and Interaction Analysis in Videos
Group Detection and Tracking using Sociological Features
S. Vascon, and L. Bazzani
Group and Crowd Behavior for Computer Vision, 2017
Online Bayesian Non-Parametrics for Social Group Detection
M. Zanotto, L. Bazzani, M. Cristani, V. Murino
British Machine Vision Conference (BMVC), 2012
Towards Computational Proxemics: Inferring Social Relations from Interpersonal Distances
M. Cristani, G. Pagetti, A. Vinciarelli, L. Bazzani, G. Menegaz, V. Murino
International Conference on Social Computing (SocialCom), 2011
Cross-Camera Identification
Semi-Supervised Multi-Feature Learning for Person Re-Identification
D. Figueira, L. Bazzani, H.Q. Minh, M. Cristani, A. Bernardino, V. Murino
International Conference on Advanced Video and Signal-based Surveillance (AVSS), 2013
Person Re-Identification with a PTZ Camera: An Introductory Study
P. Salvagnini, L. Bazzani, M. Cristani, V. Murino
International Conference on Image Processing (ICIP), 2013
Multiple-Shot Person Re-Identification by Chromatic and Epitomic Analyses
L. Bazzani, M. Cristani, A. Perina, and V. Murino
Pattern Recognition Letters (PRL), 2012
Multiple-Shot Person Re-Identification by HPE Signature
L. Bazzani, M. Cristani, A. Perina, M. Farenzena, V. Murino
International Conference on Pattern Recognition (ICPR), 2010
🦄 Personal Projects

Music Album: Accepted Insanity
As long-time keyboardist, I am currently composing and producing original synthwave music. This album explores the insanity that sorrounds us but we are somehow programmed to accept.
Personal Hybrid Training Planner
As a runner and passionate about strength training, I created a personalized planner that leverages AI to build highly personalized, multi-week training plans tailored to your specific requirements.